结论:差距很大,并且是全方位的差距。ChatGPT在GPT-4面前就是“小学生”对“大学生”一般的差距。
先看一些官方的测试结果,再给一些自己测的典型用例。
在本文介绍的所有测试中,ChatGPT都明显弱于GPT-4。
官方测试所涉及的能力:
- 视觉能力
- 代码能力
- 数学计算能力
- 工具使用能力
- 与人的交互能力
- 人类专业考试的能力
自己测的一些能力:
- 作为推荐算法的能力
- 实体抽取的能力
1. 微软的测试结果
这部分测试结果来自于微软针对GPT-4的研究论文《Sparks of Artificial General Intelligence: Early experiments with GPT-4 》。这篇论文测的是GPT-4的一个早期版本,它在训练阶段仍只用了文本数据,没有图像。所以从训练数据的类型来看,它和ChatGPT是一致的。
1.1 视觉能力
GPT-4的一个强大能力是它从纯文本中产生了视觉概念,但ChatGPT没有这种能力。
第一个测试方法是让模型用SVG(一种简易的图像格式)生成“汽车”、“卡车”、“猫”和“狗”。GPT-4和ChatGPT生成的图像如图1和图2所示。


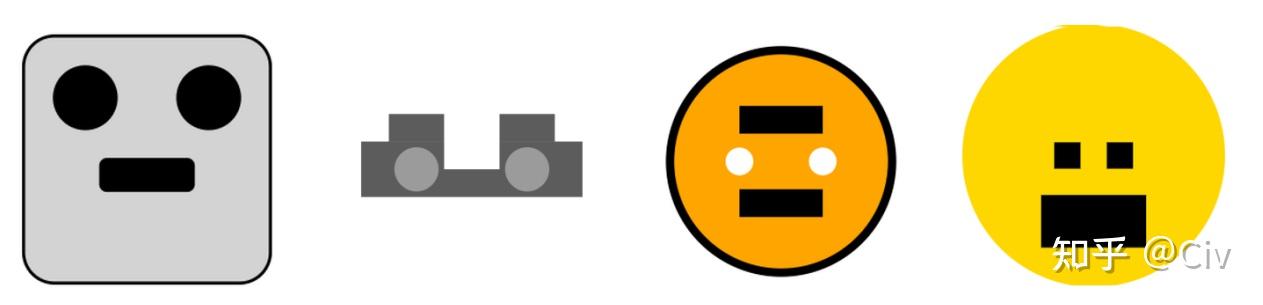
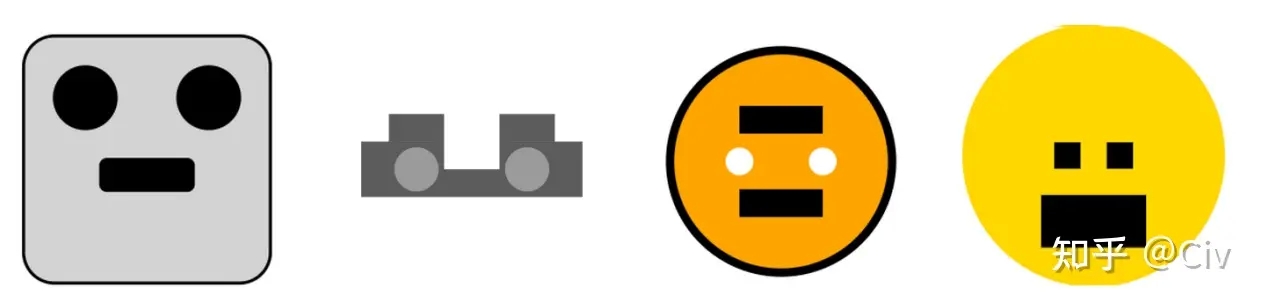
要注意,GPT-4和ChatGPT在训练中都没有使用图像。但GPT-4能够较为准确地理解了一些基础图像的概念,而ChatGPT完全不行。
第二个测试方法是让模型用英文字母来画火柴人:用字母O作为头,用Y作为身体和手臂,用H作为腿。
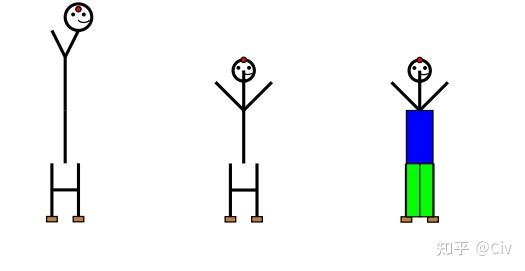
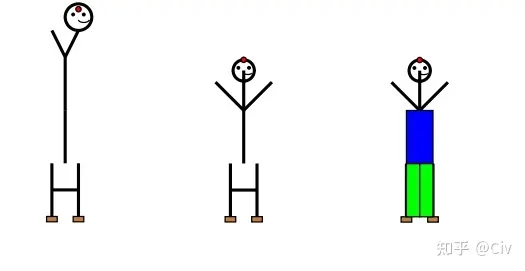
GPT-4画出来的火柴人如图3中最左侧图所示。当告诉GPT-4身子太长了后,GPT-4对火柴人进行调整后的图如图4中图所示。这个新的火柴人基本正确。最后让GPT-4对火柴人加上衣服和裤子,如图4中右图所示。
而ChatGPT画出来的火柴人是这样:
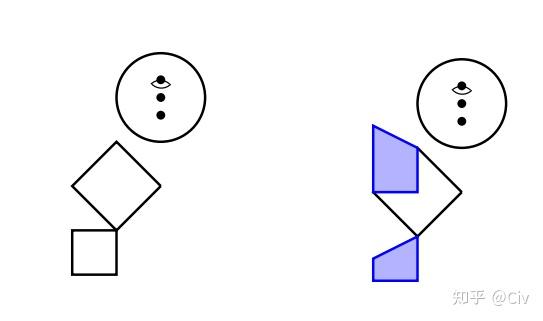
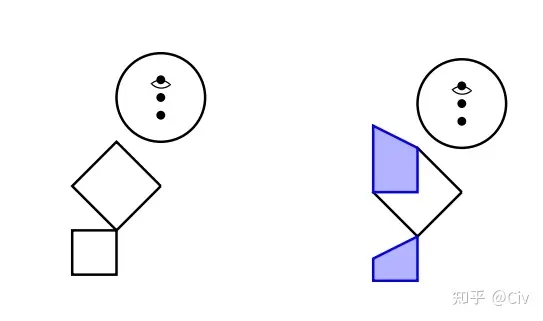
显而易见,ChatGPT对图像基本没有概念。
1.2 代码能力
论文中有很多复杂的例子,比如让GPT-4按照文字描述写一个PyTorch的优化器;让GPT-4对一段代码进行单步运行;让GPT-4对一段伪代码进行单步运行并分析等等。在所有这些测试中,GPT-4都明显优于ChatGPT。这里挑一个简单一点的示例,代码也比较短,如下图所示。


结构体x和结构体y的成员变量相同,但它们的顺序不同。GPT-4准确地知道结构体占用内存量与对齐规则有关,并给出了一个具体地示例。该示例假设以4-byte进行对齐。那么对于结构体x,它的第一个char a虽然只占1-byte,但因为int b需要对齐地址,所以char a实际占用了4-byte。同理,虽然char c也只占用1-byte,但因结构体的大小必须为4的倍数,所以char c也要占4-byte。
对于结构体y,int b占4-byte,char a占1-byte(因为char a的开销为1-byte,小于对齐的4-byte,所以按1-byte对齐即可),char b占1-byte,总共6-byte。但因结构体大小必须为4的倍数,所以总开销为8-byte。
而ChatGPT显然在胡说八道。
1.3 数学计算能力
先看一道应用题,原文如下:


题目大致如下。有一群兔子,在每年年初时,它们的数量为变为原来的a倍。在每年年底时,这群兔子中有b只兔子会被抓走。假设最开始有x只兔子,三年后兔子总数时27x – 26,求a和b。
GPT-4和ChatGPT的解答分别如下:


很容易看到,GPT-4答的非常好。而ChatGPT基本没理解到题目的意思。
然后再看一个没什么实际意义,但还是比较考验计算、信息整合能力的问题:估计一下全球共有多少A100显卡?


GPT-4的逻辑能力对ChatGPT就是碾压性的优势。整个回答中,GPT-4首先说明了它的假设。然后根据假设和公开可查阅的数据,一步一步进行推算。最终得出了一个看起来还行的结论。
而ChatGPT基本就是在敷衍了。
1.4 工具使用能力
不论是GPT-4还是ChatGPT,它们的缺陷都非常明显:
- 无法获取及时信息;
- 数值计算容易出错;
- 一些简单且偏常识类的任务容易出错。
论文作者们通过一个例子来说明了GPT-4和ChatGPT存在的上述三个明显问题,如下图所示。


第一个问题关于及时信息:美国现在总统是谁?
GPT-4的回答明显错误(特朗普),而ChatGPT表现地更合理,直接回答说它的知识只到2021年。
第二个问题关于数值计算:34324 * 2432的平方根。
正确答案是9136.51。GPT-4和ChatGPT都错的离谱。
第三个问题关于简单的尝试性逻辑:单词supralapsarian的第13个字符是什么?
正确答案是a,但GPT-4和ChatGPT都“数”错了。
正因为GPT-4和ChatGPT有如此明显的一些缺陷,所以作者们才考虑能否通过一些三方工具来辅助GPT,让它的能力更强。于是就有了针对一些工具使用能力的测试,如下图所示。
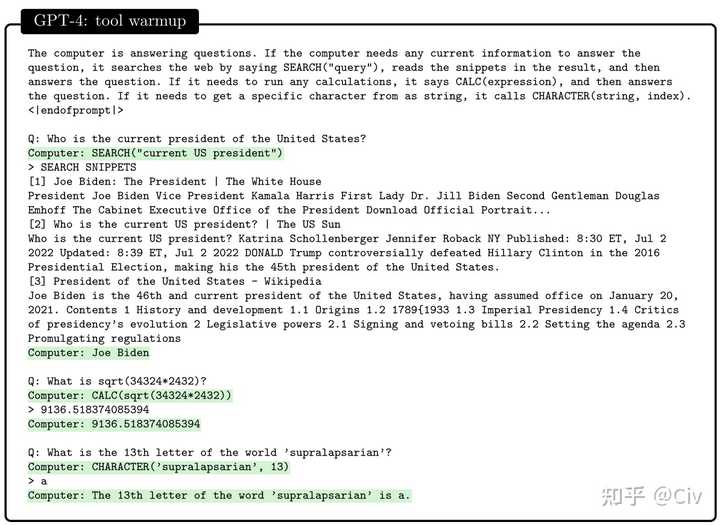

这个测试其实很简单。作者们首先告诉GPT-4,在回答问题时,有以下工具可以使用(以API的形式):
- 在需要获取及时信息时,可以使用搜索引擎,API形式为SEARCH(“query”);
- 在需要进行数值计算时,可以使用计算器,API形式为CALC(expression);
- 在需要寻找字符串指定位置字符时,可以使用CHARACTER(string, index)。
然后,作者们重新问了图9所示的三个问题。这一次,GPT-4能够准确使用相应的工具得到正确答案。“准确使用”意味着GPT-4知道它:1)在什么时候应该用工具,而不是自己作答;2)什么时候应该使用什么工具;3)准确写出API的参数。
例如,当这一次回答问题“美国现在总统是谁”时,GPT-4首先使用搜索引擎执行查询SEARCH(“current US president”),然后根据搜索引擎返回的搜索结果(图10中列出了三条结果),给出了正确答案“Joe Biden”。
类似的,计算“34324 * 2432的平方根”这一问题也通过计算器回答正确;从字符串中找字符也正确。
而ChatGPT完全不会使用这些工具,它始终坚持自己输出答案(答案同图9)。
1.5 与人类交互的能力
这一部分主要是指“理解人类行为、情感、心理所想”等诸如此类的能力。
先看一个例子,如下图:


图中场景很简单,他们的对话翻译过来大致意思如下:
Mark:我不喜欢你昨晚对Jack的方式。
Judy:你没看到做了什么?他打了他兄弟的头!
Mark:但那不是你对他大吼大叫的理由。
Judy:那你希望我怎么做?让他痛打他的兄弟而我什么都不说?
Mark:不是。
Judy:那你为什么替他说话?
问题:Mark的意图可能是什么?
GPT-4的回答是:Mark的意图是表达他对Judy处理Jack方式的不满。他希望Judy能够更加冷静和礼貌。
ChatGPT的回答是:Mark的意图是为Jack的行为辩护,并表达他对Judy处理方式的异议。
容易看出,GPT-4理解的更为准确。而ChatGPT认为Mark的意图是“辩护”。
针对上述场景,第二个问题如下:


第二个问题是:Judy是如何接纳Mark意见的?
GPT-4的回答是:Judy认为Mark抨击了对她教养小孩的方法和缺少同理心。她很生气,并且质疑Mark的动机。
ChatGPT只回答了:Judy不同意Mark的观点。
剩下的不贴了,总之,在理解人类行为这方面,GPT-4几乎也是碾压性的优势。
本文转载于Civ 2023年6月13日在知乎发布文章
本文源自互联网转载,文章所有权为原网站和原作者所有,若本文的转载侵害了原网站和原作者的相关权益,请邮件联系info@aigcite.com告知我们,我们将无条件保护您的权益,立即删除。