Stable Diffusion生图越来越快,TensorRT扩展实现SD秒速生图
随着SDXL的发布,Stable Diffusion生成图像的质量再上一个台阶。相比SD 1.5,SDXL的模型增大了约3倍,图像质量提升的代价就是需要更长的时间来出图。图像生成质量固然重要,出图速度也是实际生产比较关注的点,特别是对普通用户。好在,最近的一些工作也开始关注提升出图速度,比如最近通过模型压缩来提升速度的SSD-1B以及通过模型蒸馏来加速的LCM。除此之外,NVIDIA官方最近也发布了Stable Diffusion Web UI 的TensorRT 加速插件,可将 GeForce RTX 性能提升至高达 2 倍,这在不影响出图质量的前提下可以大幅提升SD图像的生成速度,使拥有消费级显卡的普通用户能够加速迭代。
Stable Diffusion简介
Stable Diffusion可以说是目前最受欢迎开源文生图模型。SD是建立在latent diffusion架构基础上,相比pixel diffusion架构,latent diffusion采用一个autoencoder模型来将图像压缩为一个更小的latent,这样就可以大大降低diffusion model所需的计算量,只需要一个扩散模型就可以生成512×512以上的图像。
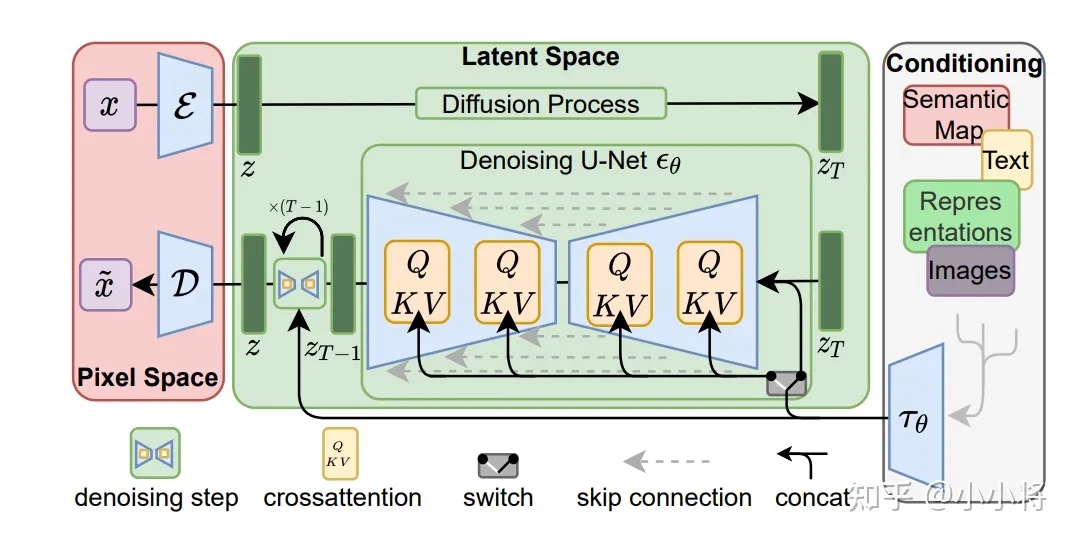
目前SD已经发布了三个版本:SD 1.x、SD 2.x和SDXL。SD 2.x相比SD 1.x提升不是很明显,但是SDXL的UNet参数量比SD 1.x大了约3倍,而且集成了更强的text encoder,所以生成图像的质量有明显的提升。

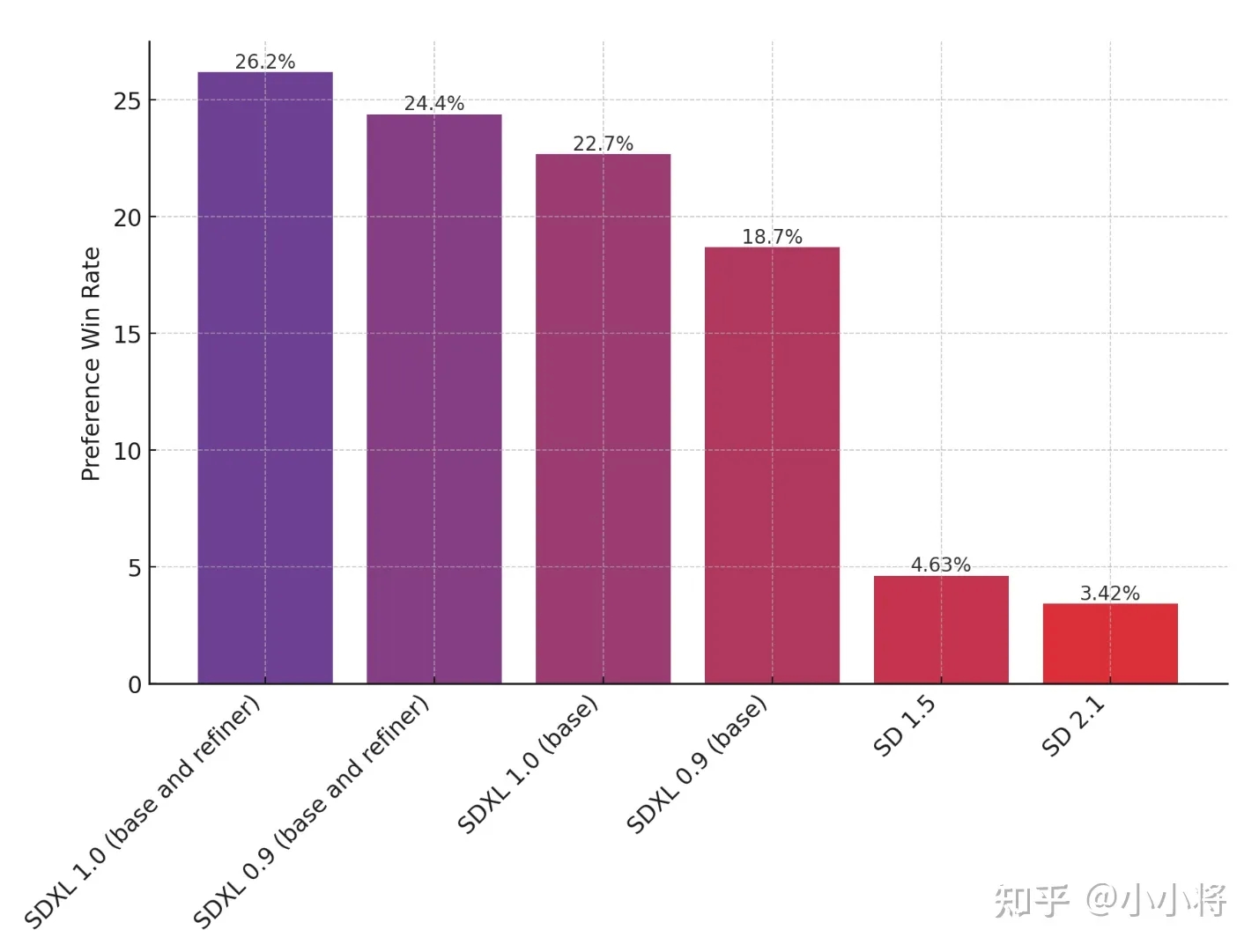
相比SD 1.x,SDXL的另外一个优势是可以直接生成1024×1024的图像。虽然SDXL比SD 1.x的成图质量有明显优势,但是模型变大,生成图像尺寸变大,这些都增加了生成图像所需的时间,比如SDXL生成一张图像需要约6s,而SD 1.5只需要不到2s。出图速度对于用户迭代还是非常关键的,下面我们将介绍一下目前在SD的一些最近进展,它们都是致力于让提升SD的成图速度,特别是TensorRT可以不损失质量的前提下提升速度。
SSD-1B:为SDXL瘦身
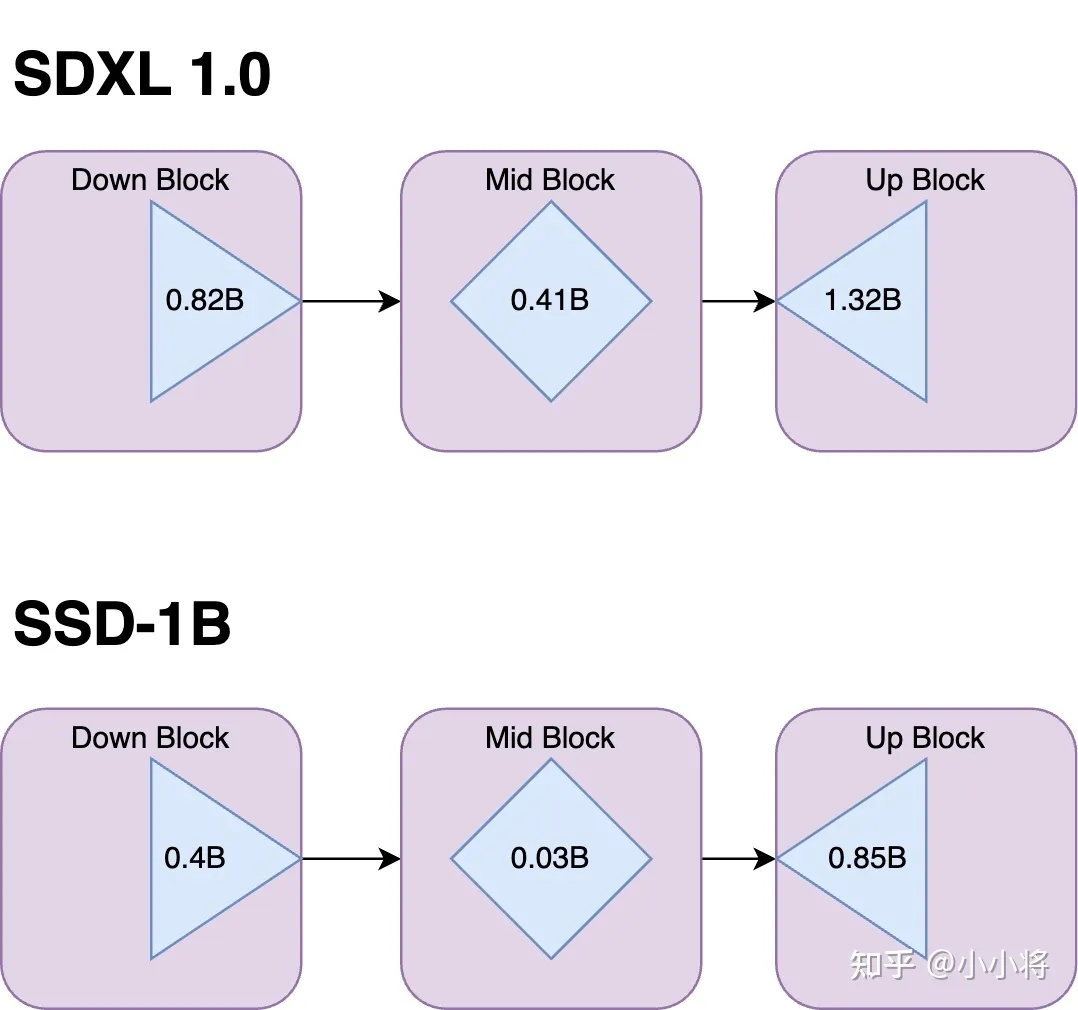
最近Segmind在SDXL基础上发布了一个蒸馏版本的模型SSD-1B,相比SDXL,SSD-1B的UNet参数量下降了50%(1.3B vs 2.6B),生成速度提升了50%,而且模型的生成效果相比SDXL没有明显下降:

简单来说,SSD-1B通过模型压缩来为SDXL瘦身,相比SDXL,SSD-1B去除了一部分层,所以参数量有一个下降:
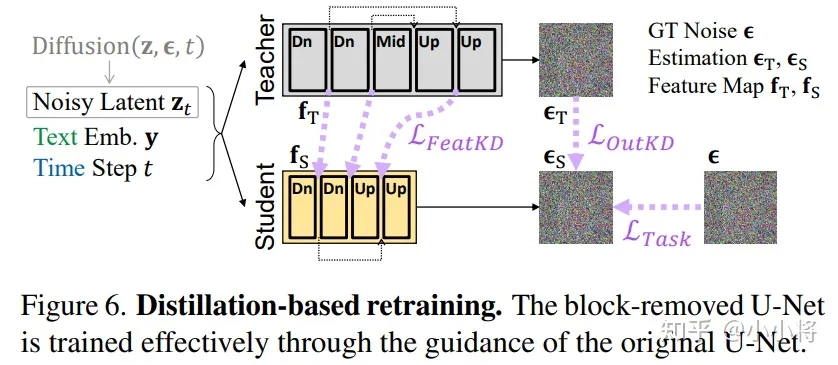
同时通过模型蒸馏来让压缩后的SSD-1B学习SDXL原来的生成能力,在技术上是基于BK-SDM中所提出的特征蒸馏方案:
使用NVIDA的RTX40系列显卡,SSD-1B相比原来的SDXL能够提速40%以上:
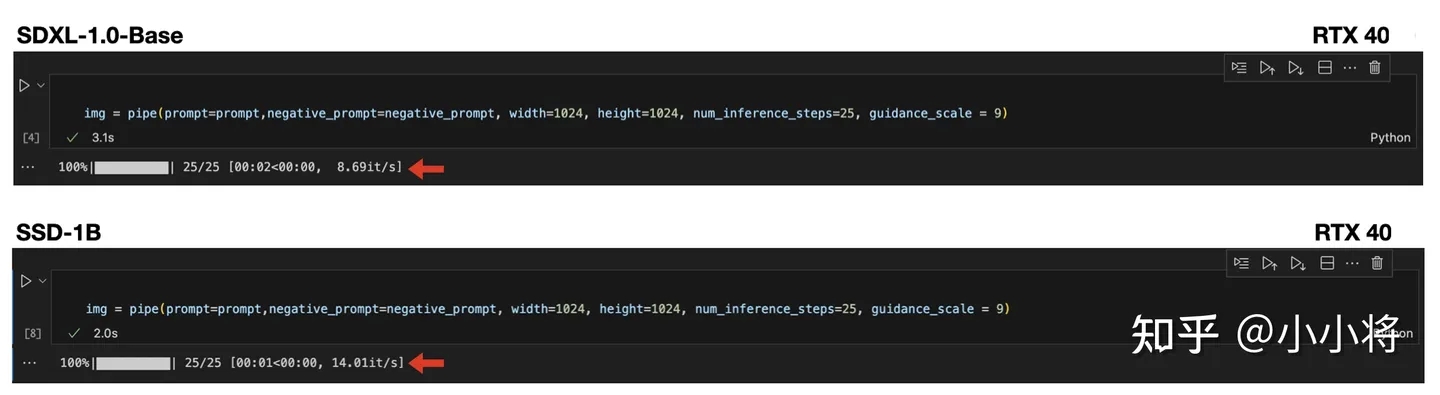
而且最重要的是,目前SSD-1B已经在SD WebUI和ComfyUI支持了!同时效果更好的SSD-1B v2也在路上了。
LCM:让SD只要4步成图
扩散模型的生成过程需要多步去噪,比如SD往往需要20~30步才可以生成一张高质量图像,所以这个生成过程就比较费时。近期比较火的LCM就是通过降低去噪步数来提升生成速度,LCM只需要4步就可以生成一张相对较好的图像,这个加速就比较明显,比如之前需要20步成图,现在只需要4步,就可以加速5倍。

LCM在技术上是采用consistency model中所提出的一致性蒸馏方案对SD 1.5或者SDXL进行蒸馏:

最早的LCM是微调整个模型,这对限制它的应用范围,比如不能迁移到其他基底模型上。而最新版本的LCM-LoRA是采用LoRA的方式来微调模型,这样就避免了改变了原始SD的UNet权重,也就可以适配不同的基底模型和风格化LoRA模型,也兼容ControlNet等可控工具。
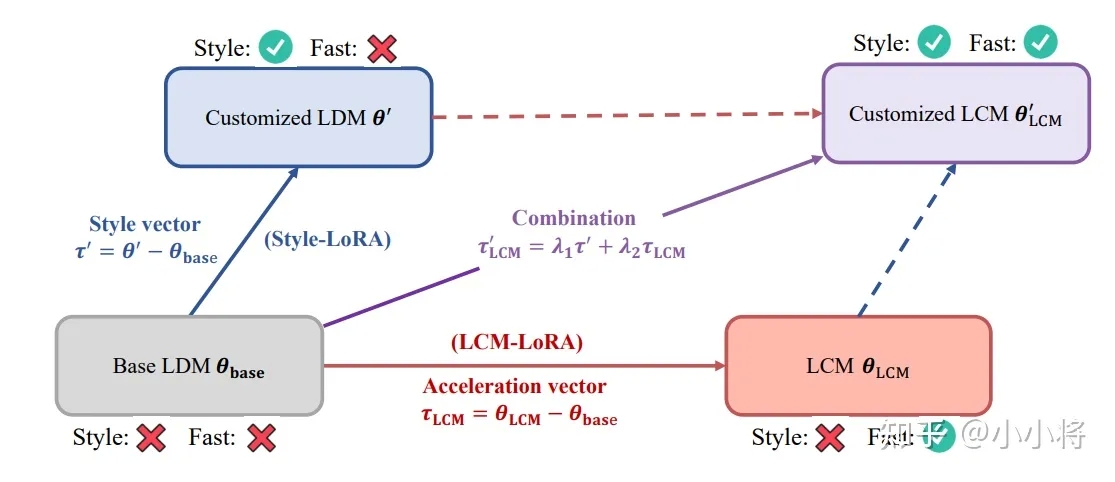
目前LCM-LoRA有SD 1.5、SDXL和SSD-1B三个版本,它们可以直接应用在对应模型上,而且只需要4步就可以生成相对不错的图像。

LCM虽然生成质量会差一些,但是可以用于实现实时的生成,比如在线图生图。目前LCM也已经集成到SD WebUI和ComfyUI中。
TensorRT:让SD无损加速,秒速生图
虽然SSD-1B和LCM均可以加速生图速度,但是它们都在一定程度上会损害生成图像的质量。如果要实现无损加速,那么最直接的方式就是采用NVIDIA官方的TensorRT来进行加速。TensorRT是NVIDIA官方推出的针对深度学习模型推理优化的一套工具,它可以让使用NVIDIA GPU的模型推理速度大幅度提升。
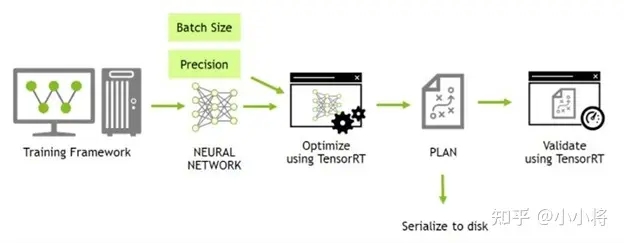
NVIDIA官方在最近也支持了Stable Diffusion WebUI TensorRT扩展,这个扩展直接支持在大家常用的WebUI使用TensorRT来加速生成图像。
如果使用拥有Tensor Cores的NVIDIA GeForce RTX 40系列显卡,相比原生PyTorch有2~3倍的加速。比如采用RTX 4080显卡,原来需要2s才能出一张512×512的图像,但是加上TensorRT扩展后,只需要0.8s出一张图,如果批次设置为4,只需要0.6s出一张图。 RTX 40系列显卡+TensorRT让SD绘画进入“秒速时代”!
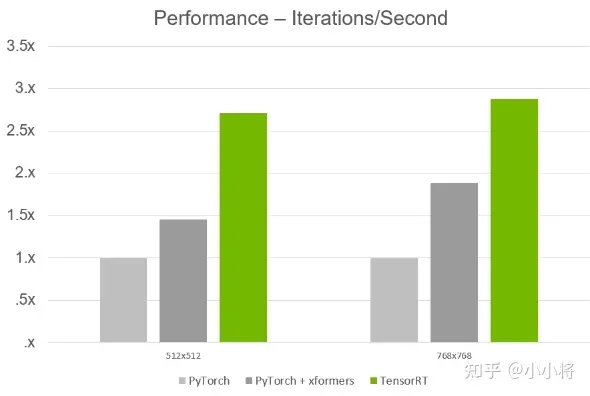
之所以这么硬核,是因为NVIDIA的RTX 40系列显卡,采用先进的NVIDIA Ada Lovelace 架构,而且拥有第四代Tensor Cores,不仅可以为游戏玩家带来极致的体验,更重要的是它可以加速AI计算,特别适合目前比较火的AI绘图工具。所以SD WebUI TensorRT插件的发布,将是只普通AI绘画创作者的福音,因为只需要配备消费级RTX 40系列显卡就能大大加速创作迭代,让用户实现SD生图自由。

而且,NVIDIA还在最近发布了可以运行在Windows PC上TensorRT-LLM,它让普通用户只需要使用NVIDIA GeForce RTX 40显卡就可以在本地部署一个私有的LLM模型,比如比较火的Llama 7B和Mistral 7B,其中RTX 40显卡使用TensorRT-LLM可以带来高达5倍的推理性能提升。
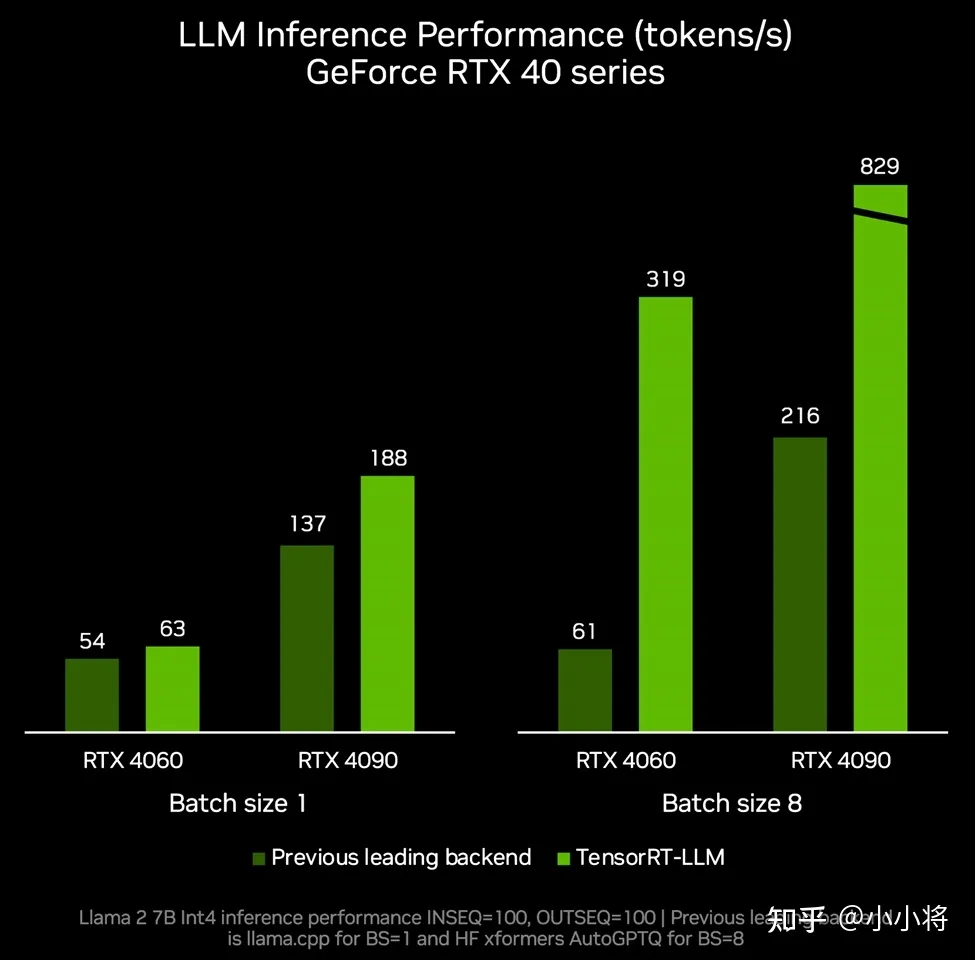
这意味着SD用户完全可以使用LLM模型来进行SD的提示词优化,从而加速出图的迭代。也不得不感叹NVIDIA GeForce RTX 40系列显卡真强,让AIGC在本地PC上运行越来越快。

总结
本文总结了最近关于SD模型的加速进展,SSD-1B通过模型瘦身来加速,而LCM通过模型蒸馏来进行加速,但是两者的问题是可能无法带来极致的出图体验。如果追求出图质量的话,还是推荐采用TensorRT来进行加速,特别是当配置RTX 40系列显卡时,出图速度有明显的提升,而且还可以使用TensorRT-LLM来部署专有的LLM模型。
参考
- https://arxiv.org/abs/2307.01952
- https://huggingface.co/segmind/SSD-1B
- https://latent-consistency-models.github.io/
- https://arxiv.org/abs/2311.05556
- https://github.com/NVIDIA/Stable-Diffusion-WebUI-TensorRT
- https://github.com/NVIDIA/Tenso
本文转载于小小将 2023年11月24日在知乎发布文章
本文源自互联网转载,文章所有权为原网站和原作者所有,若本文的转载侵害了原网站和原作者的相关权益,请邮件联系info@aigcite.com告知我们,我们将无条件保护您的权益,立即删除。