4月24日,苹果开源了大语言模型OpenELM。这与微软刚开源的Phi-3 Mini类似,是一款专门针对手机等移动设备的模型。
OpenELM有指令微调和预训练两种模型,一共有2.7亿、4.5亿、11亿和30亿4种参数,提供生成文本、代码、翻译、总结摘要等功能。
虽然最小的参数只有2.7亿,但苹果使用了1.8万亿tokens的数据进行了预训练,这也是其能以小参数表现出超强性能的主要原因之一。
值得一提的是,苹果还把训练OpenELM模型的深度神经网络库CoreNet也开源了,仅1天多的时间Github就超过1100颗星。苹果的MobileOne、CVNets、MobileViT、FastVit等知名研究都是基于CoreNet完成的。
开源地址:https://huggingface.co/collections/apple/openelm-instruct-models-6619ad295d7ae9f868b759ca?ref=maginative.com
CoreNet地址:https://github.com/apple/corenet?ref=maginative.com
论文地址:https://arxiv.org/abs/2404.14619

目前,大模型领域主要分为开源和闭源两大阵营,国内外知名闭源的代表企业有OpenAI、Anthropic、谷歌、Midjourney、Udio、百度、科大讯飞、出门问问、月之暗面等。
开源阵营有Meta、微软、谷歌、百川智能、阿里巴巴、零一万物等。苹果作为手机闭源领域的领导者,本次却罕见地加入开源大模型阵营,可能在效仿谷歌的方式先通过开源拉拢用户,再用闭源产品去实现商业化营利。
不管咋说,苹果选择开源对于开发者、中小企业来说都是一个不错的福利。因为,与以往只提供模型权重和推理代码的做法不同,苹果发布了完整的训练、评估框架等。
主要内容包括数据准备、模型训练、微调以及评估流程,同时提供了多个预训练检查点和训练日志,可以让我们深度了解全球顶级科技公司的技术思想和开发流程。
OpenELM架构简单介绍
OpenELM采用了无编码器的transformer架构,并在多个方面进行了技术创新。OpenELM的使用了一种“层级缩放”策略,使得模型能够跨各个转换器层更有效地分配参数,能以最少的训练数据取得了更好的性能,同时极大提升准确率。
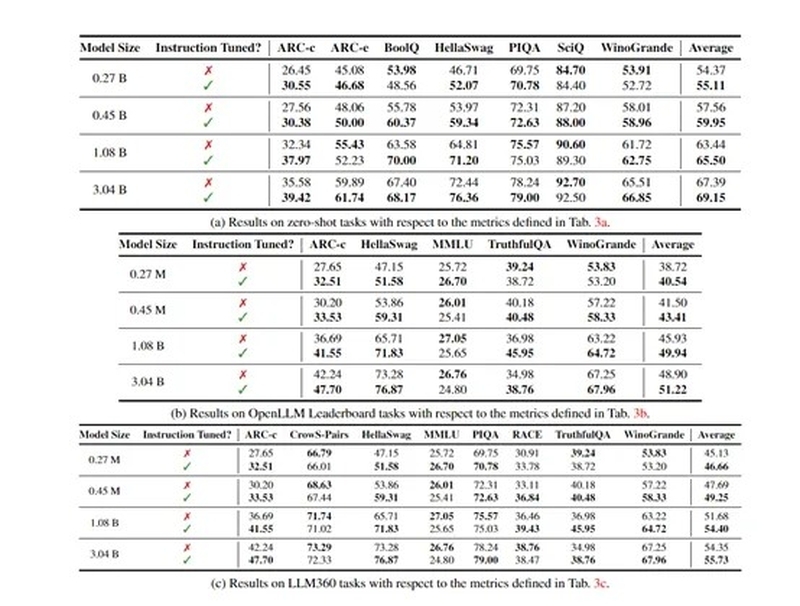
例如,11亿参数的OpenELM,比12亿参数的OLMo模型的准确率高出2.36%,而使用的预训练数据却只有OLMo的一半。
此外,OpenELM不使用任何全连接层中的可学习偏置参数,采用RMSNorm进行预归一化,并使用旋转位置嵌入编码位置信息。
OpenELM还通过分组查询注意力代替多头注意力,用SwiGLU FFN替换了传统的前馈网络,并使用了Flash注意力来计算缩放点积注意力,能以更少的资源来进行训练和推理。
训练流程与数据集
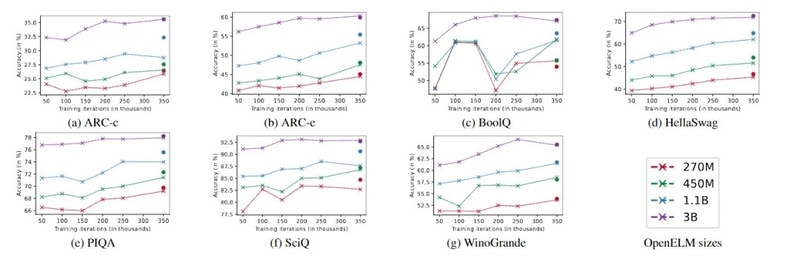
在训练流程中,苹果采用了CoreNet作为训练框架,并使用了Adam优化算法进行了35万次迭代训练。
苹果使用了批量大小为4096的小批量随机梯度下降进行模型参数更新,并设置了适当的学习率和权重衰减。
预训练数据集方面,OpenELM使用了包括RefinedWeb、去重的PILE、RedPajama的子集和Dolma v1.6的子集在内的公共数据集,一共约1.8万亿tokens数据。
此外,苹果使用了动态分词和数据过滤的方法,实现了实时过滤和分词,从而简化了实验流程并提高了灵活性。还使用了与Meta的Llama相同的分词器,以确保实验的一致性。
这次苹果真的是很有诚意的开源,一开到底所有内容都贡献出来了,家大业大就是敢玩。这也表明苹果进军大模型领域的决心,以后开源领域更热闹啦~
本文转载于微软科技2024年4月3日发布文章
本文源自互联网转载,文章所有权为原网站和原作者所有,若本文的转载侵害了原网站和原作者的相关权益,请邮件联系info@aigcite.com告知我们,我们将无条件保护您的权益,立即删除。